
Since launching our Vector Toolkit a few months ago, the number of AI applications on Supabase has grown - a lot. Hundreds of new databases every week are using pgvector.
98% of those applications use OpenAI to store embeddings using the text-embedding-ada-002 model. While OpenAI is easy, it’s not open source, which means it can’t be self-hosted.
Our goal at Supabase is to promote open source collaboration, and Hugging Face is one of the open source communities we admire most. Today, we’re adding first-class support for Hugging Face, starting with embeddings. Why embeddings? Because this is one area where open source models are measurably ahead for pgvector performance.
We’ve added support in our Python Vector Client and Edge Functions (Deno/Javascript). Let’s start with Python.
Hugging Face with Python
supabase/vecs is our Python client for vector projects. Today, we're releasing a new feature for vecs called "adapters".
Adapters transform your input into a new format when upserting and querying. For example, you can split large text into smaller chunks, or transform it into embeddings. And, of course, Adapters have first-class support for Hugging Face models.
As an example, let’s look at how we might adapt text input. If we're inserting large text documents, it might be a good idea to chunk the text into paragraphs using the ParagraphChunker before creating an embedding for each paragraph with the TextEmbedding adapter step.
_16import vecs_16from vecs.adapter import Adapter, ParagraphChunker, TextEmbedding_16_16vx = vecs.create_client("postgresql://<user>:<password>@<host>:<port>/<db_name>")_16_16# create a new collection with an associated adapter_16docs = vx.get_or_create_collection(_16 name="docs",_16 # here comes the new part_16 adapter=Adapter(_16 [_16 ParagraphChunker(skip_during_query=True),_16 TextEmbedding(model='Supabase/gte-small'),_16 ]_16 )_16)
In the example, we're using the gte-small model, but any model compatible with sentence transformers can be used in its place.
Once the adapter is registered with the collection we can upsert data using plain text and records are automatically converted to vectors:
_10# Upsert_10docs.upsert(_10 records=[_10 (_10 "vec0",_10 "the diameter of a 747 ...", # <- inserting text!_10 {"publish_year": 2019}_10 )_10 ]_10)
Similarly, queries are transparently converted into vectors:
_10# Search by text_10docs.query(data="how many ping pong balls fit in a Boeing ...")_10_10# Results: [...]
Hugging Face with Edge Functions
AI/ML is primarily the domain of the Python community, but thanks to some amazing work by Joshua at Hugging Face, you can now run inference workloads in Deno/JavaScript. This is an exciting development. It opens up the world of AI/ML to millions of new developers. We’re hoping to accelerate this with better Hugging Face tooling within Supabase Edge Functions.
Let’s step through a small demo where we accept some text, convert it into an embedding, and then store it in our Postgres database. You can create a new function with supabase functions new embed and fill it with the following code snippet:
_43import { serve } from 'https://deno.land/[email protected]/http/server.ts'_43import { env, pipeline } from 'https://cdn.jsdelivr.net/npm/@xenova/[email protected]'_43import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'_43_43// Preparation for Deno runtime_43env.useBrowserCache = false_43env.allowLocalModels = false_43_43const supabase = createClient(_43 'https://xyzcompany.supabase.co',_43 'public-anon-key',_43)_43_43// Construct pipeline outside of serve for faster warm starts_43const pipe = await pipeline(_43 'feature-extraction',_43 'Supabase/gte-small',_43)_43_43// Deno Handler_43serve(async (req) => {_43 const { input } = await req.json()_43_43 // Generate the embedding from the user input_43 const output = await pipe(input, {_43 pooling: 'mean',_43 normalize: true,_43 })_43_43 // Get the embedding output_43 const embedding = Array.from(output.data)_43_43 // Store the embedding_43 const { data, error } = await supabase_43 .from('collections')_43 .insert({ embedding })_43_43 // Return the embedding_43 return new Response(_43 { new_row: data },_43 { headers: { 'Content-Type': 'application/json' } },_43 )_43})
Now run supabase functions serve and you’re ready to call your function locally:
_10curl --request POST 'http://localhost:54321/functions/v1/embed' \_10 --header 'Authorization: Bearer ANON_KEY' \_10 --header 'Content-Type: application/json' \_10 --data '{ "input": "hello world" }'
With just 40 lines of code, we’ve created an API route that can accept some user content, convert it to an embedding, store it in your database, and then return the database row as JSON. This is especially useful for sensitive data since you can run this entirely on your own infrastructure.
Supabase also provides Database Webhooks which can trigger an Edge Function any time a row is inserted. This means you can upload plain text to your database and use a background job to convert the text to an embedding.
Hugging Face from the browser
One of the coolest ideas we’ve seen so far is the ability to support Hugging Face models directly in the browser. With sufficiently small models, you can embed them directly into your application and cut out an entire network hop.
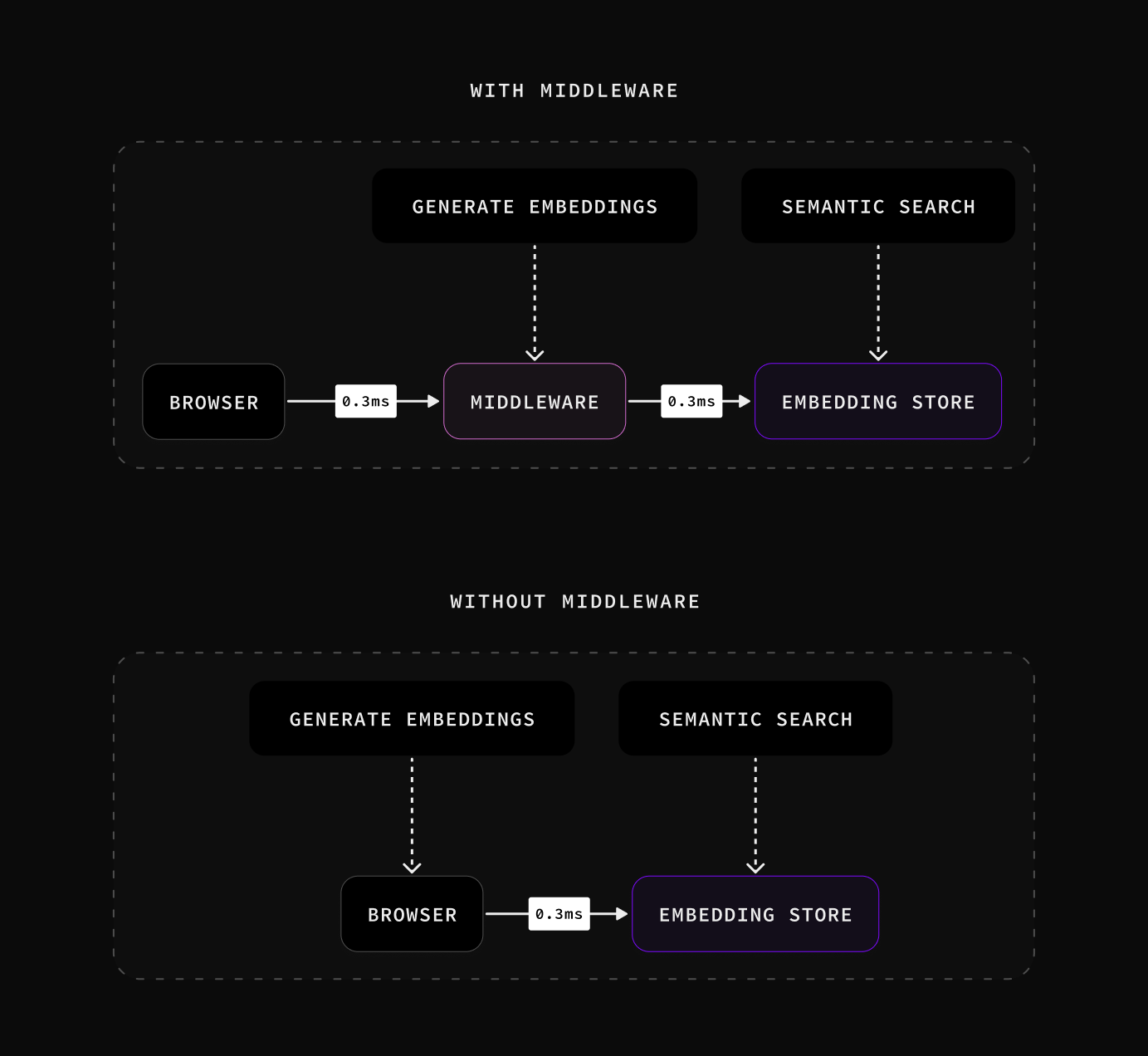
This is great for search, where you might want to “debounce” the user query as they type. Of course, this is only helpful if you have a database that allows access from the browser. Fortunately, Supabase provides that functionality using Postgres Row Level Security and PostgREST:
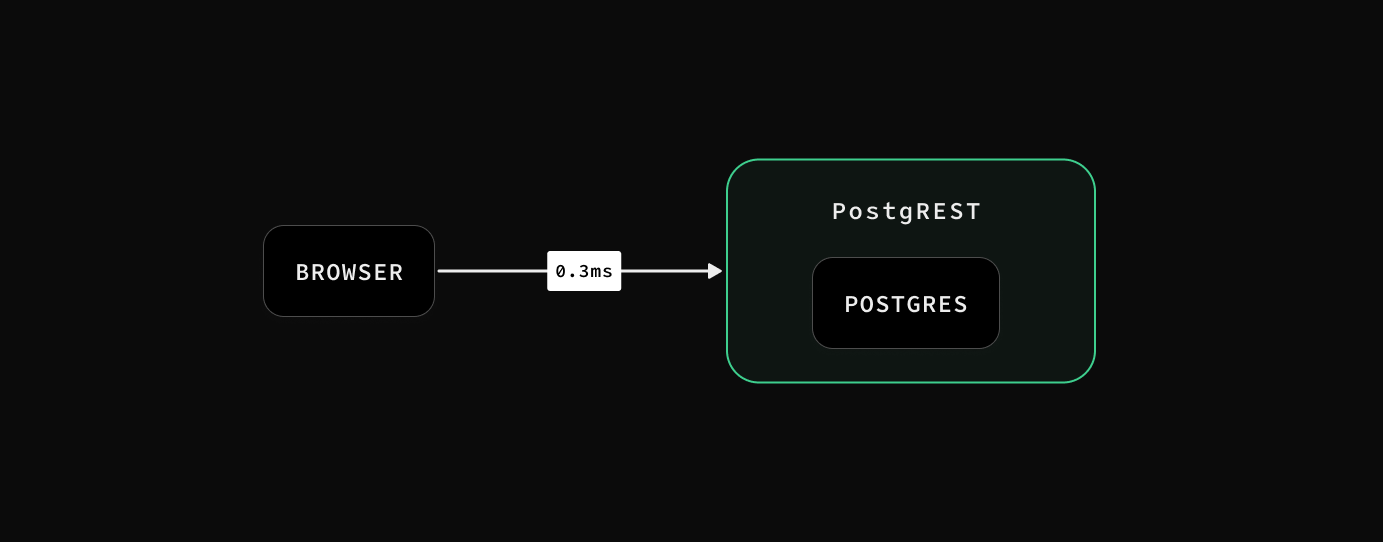
For example, if we were storing image embeddings inside our database, we could provide search functionality using a simple Postgres function, powered by pgvector:
_14create function match_images (_14 query_embedding vector(512),_14 match_threshold float,_14 match_count int_14)_14returns setof images_14language sql stable_14as $$_14 select *, 1 - (image_embedding <=> query_embedding) as similarity_14 from images_14 where 1 - (image_embedding <=> query_embedding) > match_threshold_14 order by similarity desc_14 limit match_count;_14$$;
Now, we can call that function directly from the browser using supabase-js:
_10let { data: images, error } = await supabase.rpc('match_images', {_10 query_embedding,_10 match_threshold,_10 match_count,_10})
Of course, even the smallest quantized models in the MTEB leaderboard are around 20 MB - so you won’t be seeing this on an e-commerce store any time soon. But for some web-based applications or browser extensions it’s an exciting prospect.
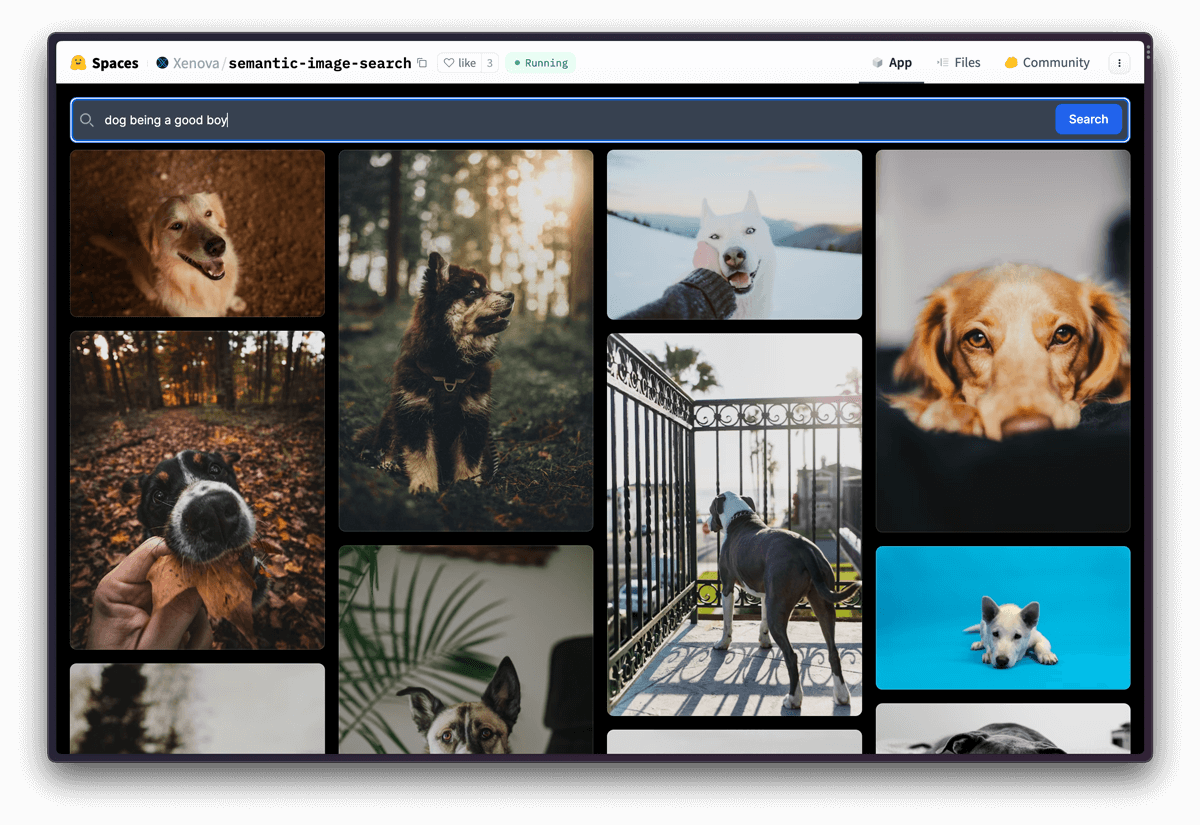
Check out this demo for inspiration, which uses the Unsplash data set and provides image search functionality using natural language:
Choosing a Hugging Face model
Supabase is mainly used to store embeddings, so that’s where we’re starting. Over time we’ll add more Hugging Face support - even beyond embeddings. To help you identify which Hugging Face model to use, we ran a detailed analysis and found that embeddings with fewer dimensions are better within pgvector. Fewer dimensions have several advantages:
- They require less space in your database (saving you money!)
- Retrieval is faster
To simplify your choice we’ve shortlisted a few recommendations in the official Supabase org on Hugging Face. The gte-small model is the best (it even outperforms OpenAI’s embedding model in some tasks), but it’s only trained on English text, so you’ll need to find another model if you have non-English text.
Remember also, you can continue to use OpenAI for generative use cases. This means you get the best of both worlds - fast embeddings with Hugging Face and advanced AI with OpenAI’s GPT-3.5/4.
Plans for the future
We’re in the early stages of development, and we have some exciting ideas to overcome the limitations of this initial release.
Reducing cold starts
Cold starts are the time it takes for the “initial load” of an Edge Function. Because the model needs to be downloaded to the Edge Function, cold starts can take anywhere from ~2-6s (based on the model). Loading the initial model and building the pipeline usually contributes to it. We are experimenting with the idea of attaching a “read-only disk” of models to our Edge Runtime which mitigate any download penalties. We’ll share more details about these optimizations in a future blog post.
Handling heavier workloads
The current quotas provided by Edge Functions are sufficient for running common embedding models. Larger AI models and tasks may require extra memory, CPU, and wall-clock limits to run successfully. We will offer customizable compute resources for Edge Functions in the next few months. If you have a workload that may require extra resources reach out for early access.
Audio and image models
Working with audio and image data in Edge Functions is a work in progress. AI models expect audio and image content to be decoded into their raw formats before performing inference, and this isn’t yet turn-key in a Deno environment.
For example, the Whisper audio transcription model requires audio to be passed in as 32-bit floating point pulse-code modulation (PCM) data sampled at exactly 16000Hz. Assuming your audio is stored in an encoded format like MP3, you first need to both decode and possibly resample the data before Whisper can understand it. In the browser, the Web Audio API is available which Transformers.js uses for decoding, but this API isn’t currently available in a Deno environment.
Images have the same challenge. Models like CLIP, which can generate embeddings from images, require images to be decoded into their raw RGBA values and sometimes resized. Transformers.js uses the Canvas API in the browser and sharp in Node.js to perform these operations, but Deno doesn’t yet have a turn-key solution (sharp uses Node.js C++ bindings).
Getting started
If you’re a Python Dev, check out our Hello World notebook. If you’re a JavaScript developer, check out our Text Embeddings docs.
And no matter your language preference, remember to jump into the Hugging Face community and show your support.