On May 27 Supabase hit the top of Hacker News and stayed on the front page for more than 24 hours.
Since then, Supabase has been featured on the Stack Overflow podcast, hit the trending page on GitHub, and scaled to over 1000 databases.
Here is everything that went wrong along the way.
Quick stats - launch week
Before we get into the details, here are some high-level numbers for the week following the launch.
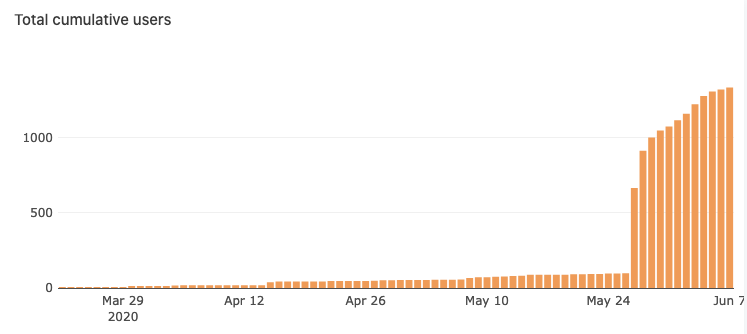
We had 30,000 new website visitors to supabase.io:
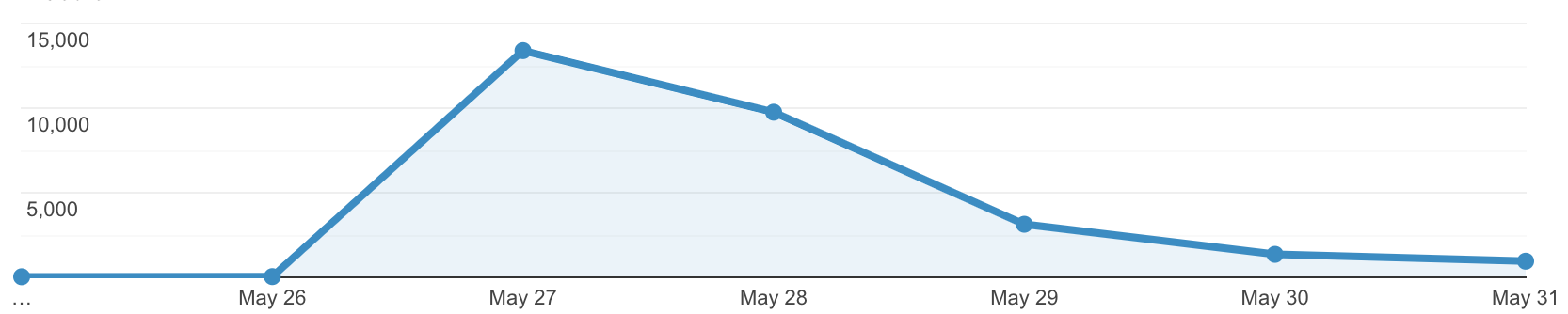
We had over 1400 signups in 7 days:
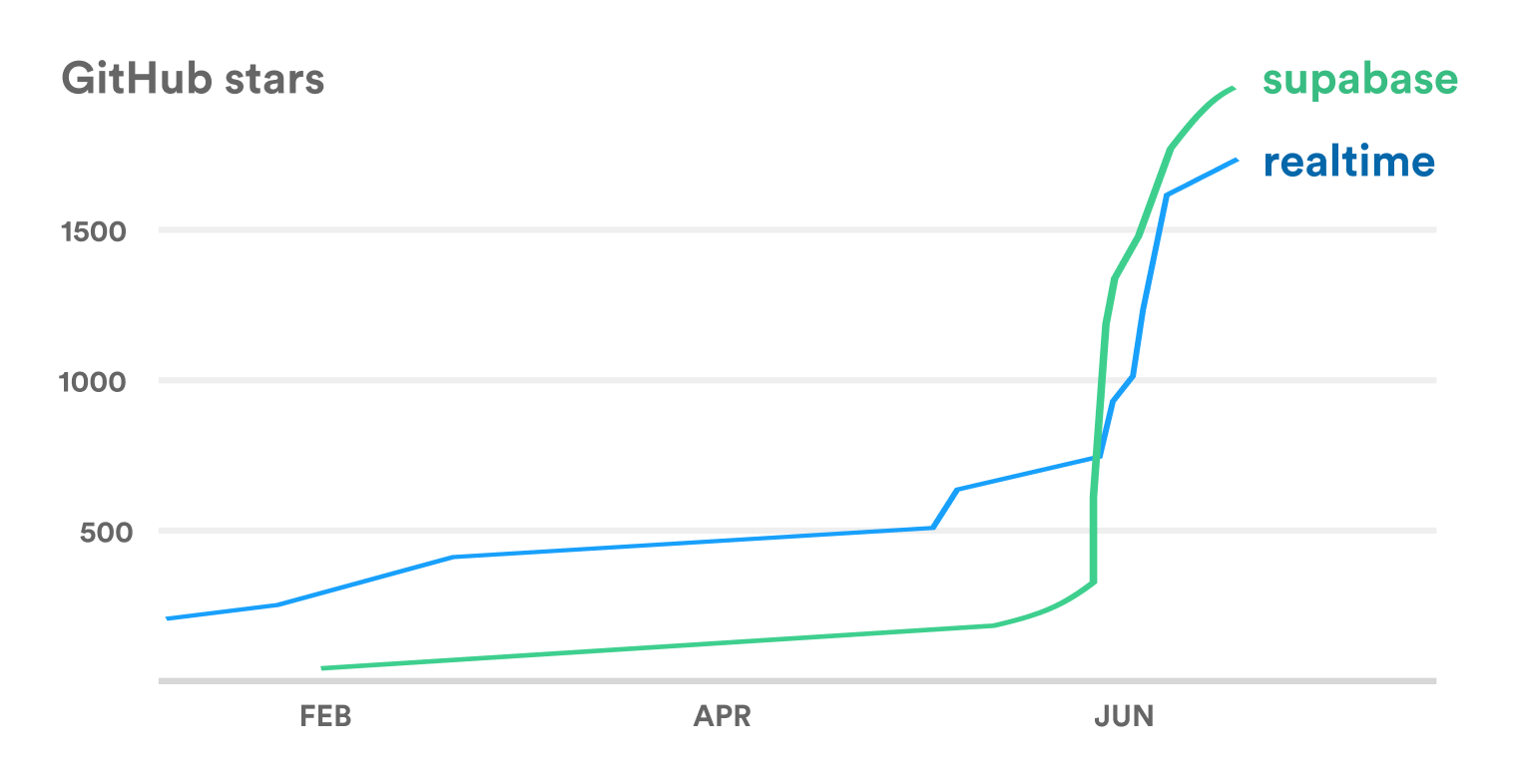
GitHub stars rocketed for our two main repos, supabase and realtime.
The good
Here are the things that survived well.
Middleware: docker compose up
This was the most surprising survivor. Our middleware was served from a single Ubuntu server with 4 CPUs and 8GB of RAM. This server was running our middleware using docker compose up:
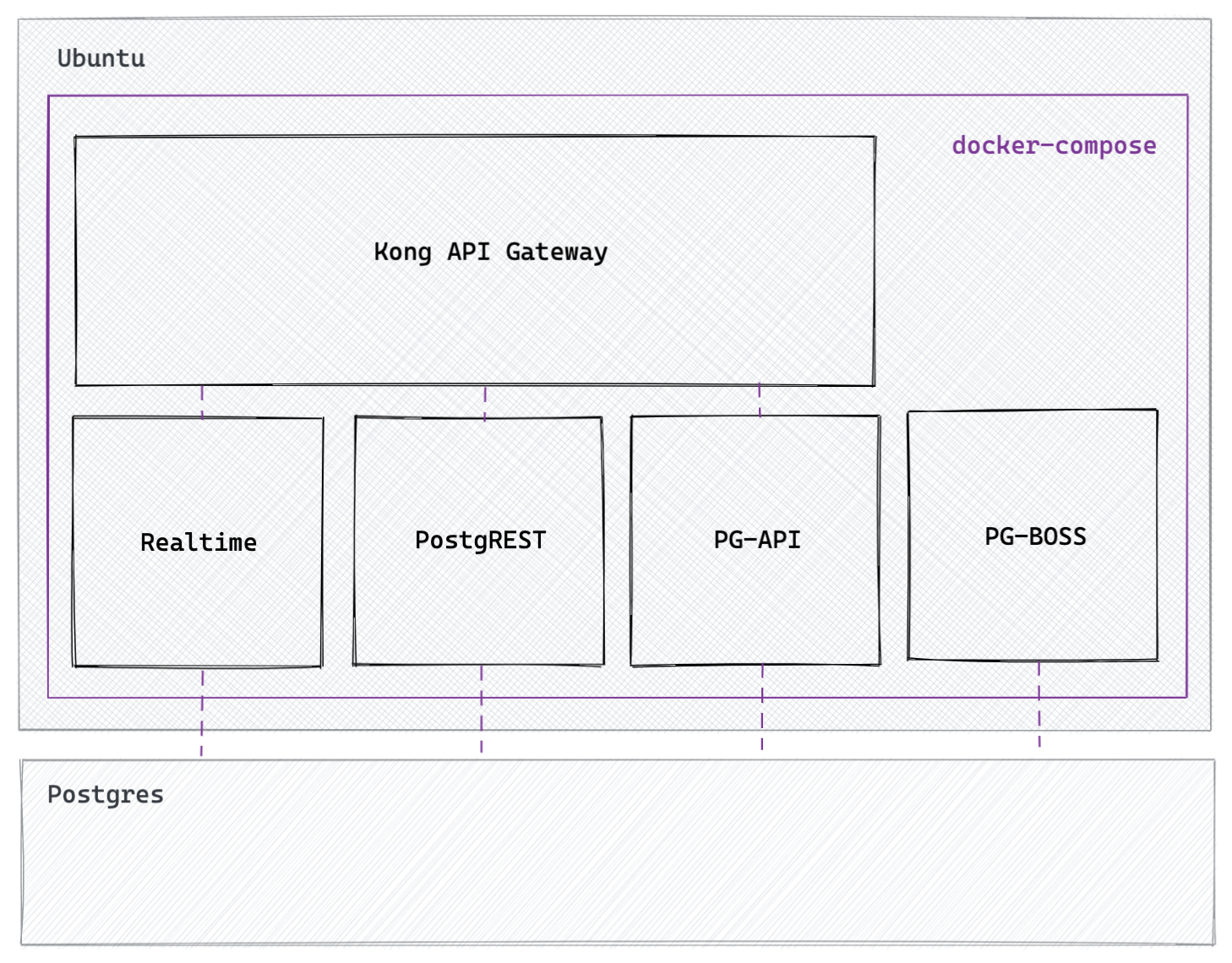
In case you're wondering why any sane company would use that in production, it's because we weren't planning to launch - the HackerNews post was created by an early GitHub follower, while we were alpha testing, and it was too scary to migrate the middleware while it was servicing the thundering herd. All Supabase projects use the same middleware stack (without docker compose), so I guess this counts as a successful load test.
We have since migrated our middleware to multiple ECS clusters, globally load-balanced using AWS's Global Accelerator.
Frontend: Netlify, Vercel, Auth0
We serve our marketing site (supabase.io) from Netlify. It's a static-build Docusaurus (v2) site, so it had no problems (apart from one developer in Russia who couldn't access the site - it looks like some of Netlify's IP addresses are blocked there).
We serve our app (supabase.com/dashboard) using Vercel, and the login system uses Auth0. These were both rock-solid. Before the launch we noticed that Vercel was extremely slow on their free plan, and once we upgraded to their Pro Plan for multi-region deploys it solved performance issues. It looks like they are changing their plans again so buyer beware.
The Bad
Digital Ocean cloud limits
In May we were using Digital Ocean to serve all of our customer databases. We hit the first server limit (400 servers) in the space of a few hours. They bumped our limit up to 1000 and we hit that again a few hours later.
Digital Ocean were very responsive when we asked for increases, each time responding in 30 minutes or less.
Cloudflare cloud limits
Each Supabase project gets a unique URL for their API and database. This is set up using Cloudflare's API. This was a seamless process until we hit the 1000-subdomain limit, at 4am in the morning. My cofounder was awake, managed to identify the problem early, and reached out to the support to increase the limit.
Cloudflare support advised him to upgrade the account to increase the limit, but the upgrade could only be done by the owner (me). Unfortunately my phone was on silent, so for 3 hours our systems were down. Ideally any one of our team could have upgraded our account, but I imagine that Cloudflare have their reasons for this restriction.
The Ugly - migrating 1800 servers
Let me start by saying that Digital Ocean have been great for getting up and running. The experience was simple to start with, but ended painfully.
Digital Ocean production errors
The first sign of problems were the frequent production errors. This is a screenshot of emails from Digital ocean for the month of June.
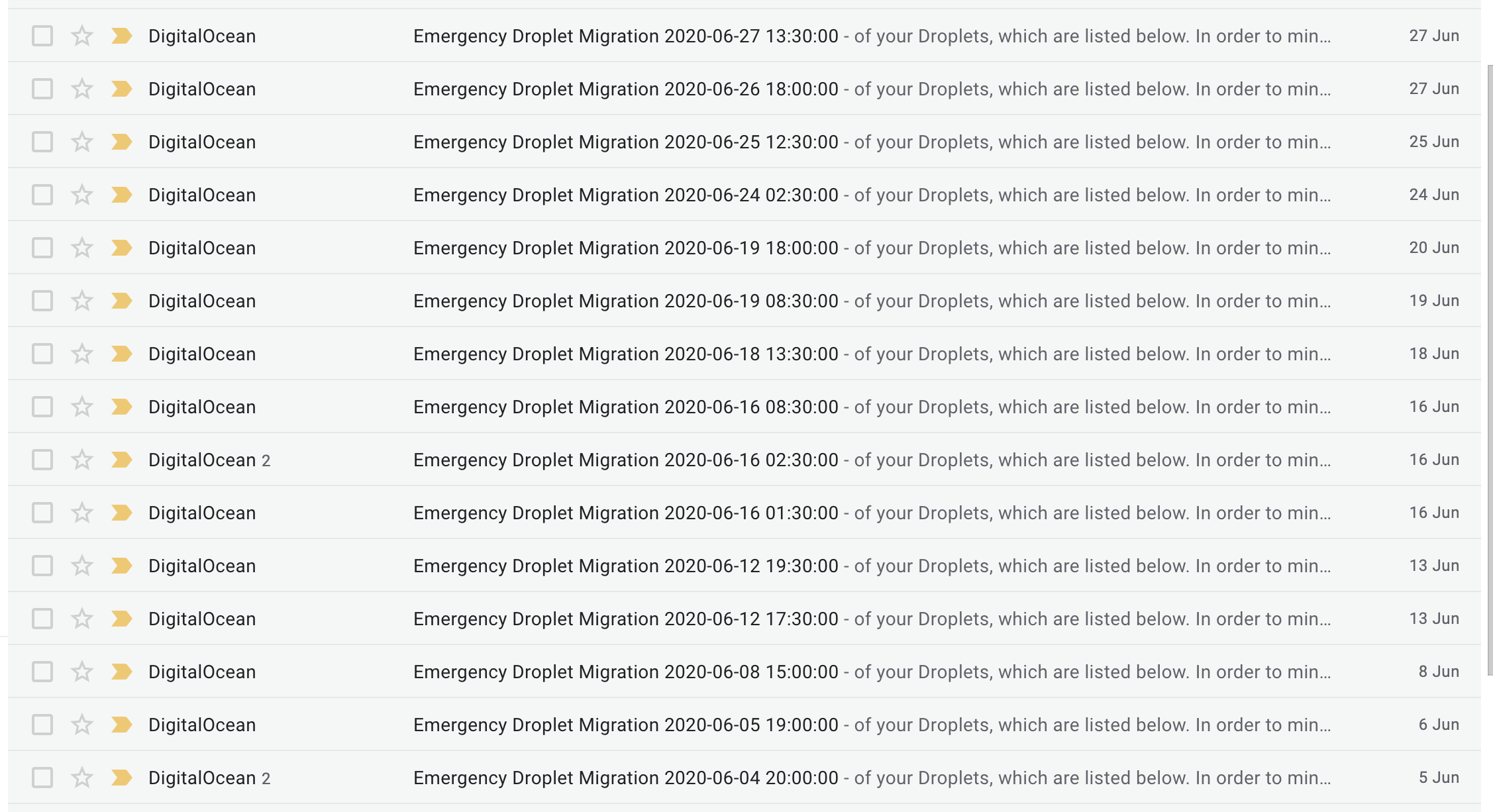
Each of these emails represents one or more servers that has a critical issue:
We have identified an issue on the physical machine hosting one or more of your Droplets. In the event that we are not able to perform a live migration of a Droplet, we will perform an offline migration during which the Droplet will be powered off and migrated offline during the window.
Luckily we are in alpha, and our community has been extremely patient.
Credit limits
Most of our frustration was due to their internal policy around credits program. We were generously granted $10,000 Digital Ocean credits in February through Stripe Atlas, and so they became our primary cloud provider.
Digital Ocean have another (more generous) credits package for YC companies. Unfortunately when we applied for this we were told we weren't eligible because it was a "Partner switch" from Stripe to YC. This was frustrating because a "Partner switch" is completely arbitrary to us as a customer.
Also we had conveniently just run out of credits. We don’t expect cloud providers to fund our inefficiencies, but we needed time to optimize our infrastructure after our surprise launch. We had assumed that the more generous credits package was guaranteed - an assumption which cost us several thousand dollars. After swift deliberation, we decided to migrate away from Digital Ocean.
Going Forward: AWS t3a
In the past 3 weeks we have migrated 1800 servers over to AWS.
We are on the AWS "Activate" program, which grants us $100,000 credits. Since Firebase has a very generous free-tier, and we want to be able to offer Supabase developers a similar experience, this is ultimately a huge benefit to our community.
The AWS team were helpful, suggesting their new t3a instances. We're already seeing improvements, with database startup times almost halved from ~90s to ~50s. From our research, this is the fastest Postgres setup in the market.
We will release a detailed write-up on these instances in the next few weeks. Sign up to our newsletter if you want to be notified when we release the post.